Historization
The history settings of a node declare how the values and events are historized.
Following nodes support historization:
A historization support following attributes:
| Attributes | Description | Data Type |
|---|---|---|
| SamplingRate | Sampling rate in milliseconds (only for streaming data classes) | System.Int32 |
| Retention | The retention attribute specifies the retention time in [hours]. Default is retention of 0 (zero) that is infinite retention time! | System.Int32 |
| HistoryTableName | Name of the history table. If empty, the default history table is used | System.String |
| IdField | Name of the entity field containing a Guid-Id (only EntityCollections) | System.String |
| TaggedFields | List of entity fields used for tags (only EntityCollections) | System.String[] |
| TrackedFields | List of entity fields used for value data (stored as key-value pairs). (only EntityCollections) | System.String[] |
Sampling
For streaming values, a sampling rate in milliseconds can be specified. For instance, use rate="1000" to sample a value with 1 Hz or rate="2000" to sample a value with 0.5 Hz.
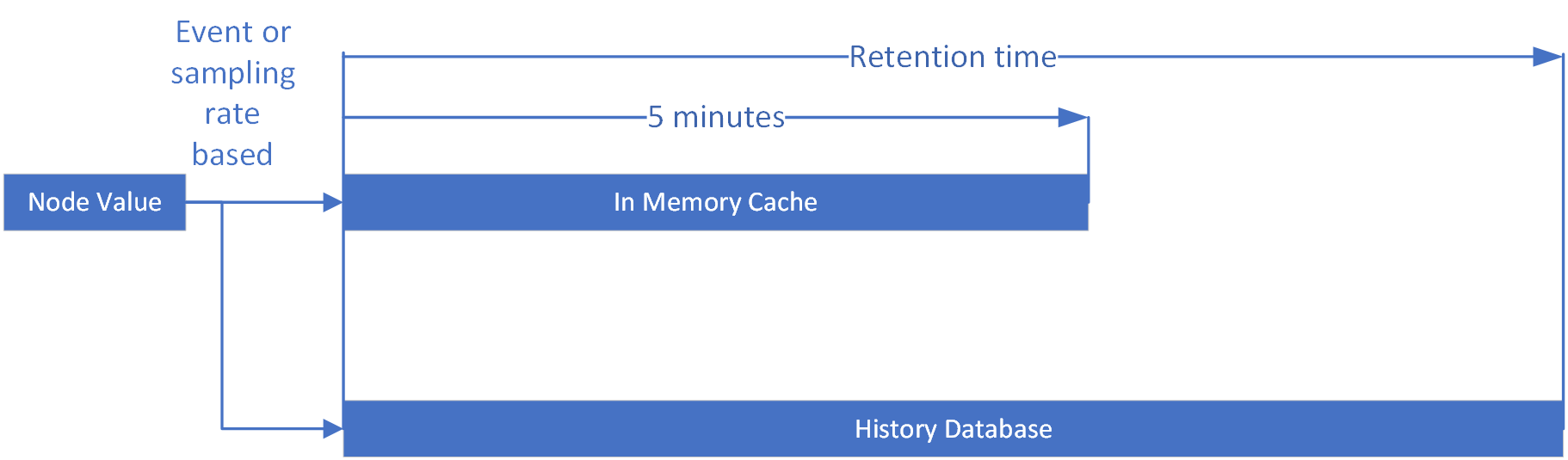
Note that if a value changes faster than the sampling rate immediate values are lost in long term tracking. However, if data persistance is chosen (like MySQL, SQlite, ...) the data are also kept in RAM about 5 minutes. This temporary storage provides a high resolution and very tracked value is kept.
Unnecessary recording of data or recording at high resolution fills your memory. This could lead to problems and system failures. Also, recording of arrays and structures need extra memory for unchanged elements within these structures!
Sample vs Event
The difference between sampling and event based is visualized as follows:

This shows that the dataclass set on the supported nodes is important. For instance a nc axis should be sample based, an operation mode event based.
History buffer
The history buffer features a high performance dual channel buffering. The most recent 5 minutes are kept in memory for fast responses and high accuracy, whilst being stored
in the database as well.
Historization of DataNode Values
Each data node can store values in a history data base.
Tagging is not supported. The Id in history table (see below) is always the node id.
Example of a data node with history:
{
"Id": "13BB68D0-3B8E-42B9-A5BC-993E5B0D49A8",
"Name": "X-Position Absolute",
"DataType": "System.Double",
"DataClass": "Stream",
"Unit": "mm",
"Address": "Nc1.Dynamic.Float64:200°1",
"Access": {
"Read": true,
"Receive": true
},
"HistoryMode": {
"SamplingRate": 2000,
"Retention": 90
}
}
Historization of AlarmEventPools
Alarms and events of an alarm and event pool can be tracked in a history data base.
The value field of the history database contains the alarm or event object as JSON. The alarms are tagged by
AlarmId. This allows to receive history of certain alarms.
Example of an AlarmEventPool with history:
"AlarmEventPool": {
"Tasks": [
{
"Address": "Nc1.NcAlarmEvent:0",
"Id": "608a08a5-046b-4089-9671-d1afb40f9d19",
"Name": "SystemAlarms",
"Properties": []
}
],
"HistoryMode": {
"SamplingRate": 2000,
"Retention": 8000
},
"Id": "2b46f903-9de5-4265-8897-225e27177016",
"Name": "MachineAlarming",
"Properties": []
}
Historization of EntityCollectionNodes
EntityCollectionNodes support a flexible historization of specific data fields.
- The Id-field of the history db contains the node id of the collection by default. It can be overwritten using a specific id of the entity object.
- Tags are generated, if the history mode declares
TaggedFields. The tag values are extracted from the entity object. - The history value is a key-value list of entity data mapped by the "TrackedFields" setting of the history mode.
Example of an entity collection with history:
{
"Id": "777EB4A2-7461-4786-AD0C-60DA9884F4BC",
"Name": "MyLibrary.Entity",
"EntityTypeName": "MyLibrary.Entity.THistorizableEntity, MyLibrary",
"HistoryMode": {
"Retention": 8000,
"HistoryTableName": "MyLibrary.History",
"IdField": "Id",
"TaggedFields": [
"OwnerId",
"Name"
],
"TrackedFields": [
"CurrentValue",
"CurrentState"
]
}
}
History with SQLite Plugin
Each historized data stream is stored in a separate db-file. The history file is located in {RepositoryFolder}\{NodeId}\history.db
The table contains following columns:
| Name | Description | DB data type |
|---|---|---|
| Id | Key: Sender Id of history data | VARCHAR(45) |
| Date | Key: Timestamp as a int64 | INTEGER |
| Value | Value of the history entry | TEXT |
| Tags | Semicolon separated list of tag-key and tag-value pairs | TEXT |
The folders and history files are automatically created when starting HumanOS.
History with MySQL or PostgreSQL Plugin
Each historized data stream is stored in a separate table within the data base. The table name is built like: {ServicePrefix}.history.{Name} where as {Name} is per default the node id.
For customized naming use the HistoryMode.HistoryTableName setting to set up a specific name for history table.
The table contains following columns:
| Name | Description | DB data type |
|---|---|---|
| Id | Key: Sender Id of history data | VARCHAR(45) |
| Date | Key: Timestamp as a int64 | BIGINT |
| Value | Value of the history entry | TEXT |
| Tags | Semicolon separated list of tag-key and tag-value pairs | TEXT |
The history tables are automatically created when starting HumanOS.
Reading History
A time range must be given to access the historical data.
For high resolution and long term history it is better to use smaller time ranges. This prevents large and long query times and possible time-outs on certain protocols like OPC-UA.
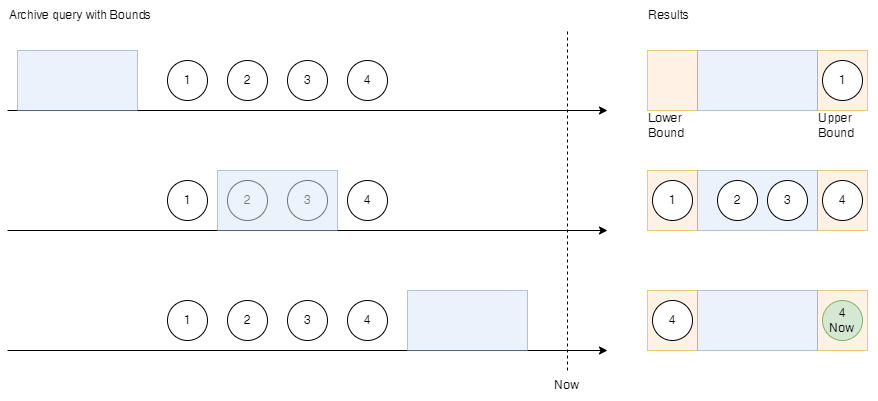
Reading with Bounds
Reading with bounds allows to get the lower and upper bound values within the queried time range. This is useful for mathematical or graphical processing of the data.
If no data is available in the time range, the upper and lower bounds are set to the closest data points.
Special case: When reading current data (or in future) the upper bound is the approximated value. Since the value has not changed since, we suppose that the data node has still the same value.